
Wie wir mit einer RAG-Pipeline Wissen für KI nutzbar machen
Einleitung
Große Sprachmodelle sind beeindruckend – doch ohne Kontext bleiben ihre Antworten oft oberflächlich oder ungenau.
In vielen realen Anwendungen ist es daher entscheidend, dass KI-Systeme auf projektspezifisches Wissen, Dokumente und strukturierte Informationen zugreifen können.
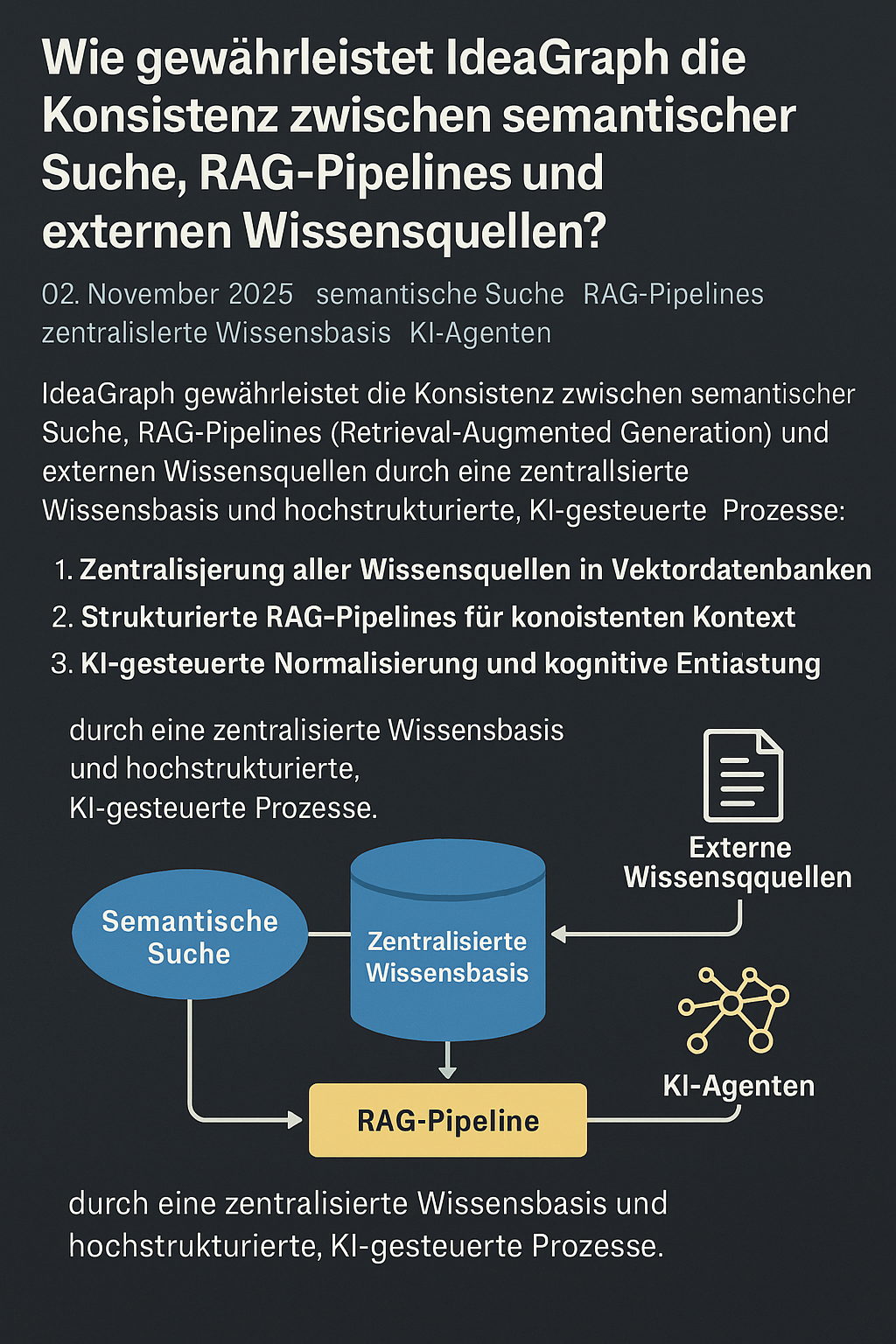
Um genau das zu ermöglichen, setzen wir auf eine RAG-Pipeline (Retrieval Augmented Generation). Sie verbindet klassische Informationssuche mit modernen Sprachmodellen und sorgt dafür, dass KI-Systeme Antworten auf Basis vorhandener Wissensquellen generieren können.
Was ist Retrieval Augmented Generation?
Retrieval Augmented Generation (RAG) beschreibt einen Ansatz, bei dem ein Sprachmodell nicht nur auf seinem Training basiert, sondern zusätzlich auf externe Wissensquellen zugreifen kann.
Der Ablauf ist dabei grundsätzlich einfach:
- Eine Anfrage wird gestellt
- Relevante Informationen werden aus einer Wissensbasis gesucht
- Diese Informationen werden dem Sprachmodell als Kontext übergeben
- Das Modell generiert auf dieser Grundlage eine Antwort
Dadurch können KI-Systeme aktuelle, projektspezifische oder organisationseigene Informationen berücksichtigen.
Unsere RAG-Pipeline im Überblick
Unsere Pipeline besteht aus mehreren Verarbeitungsschritten, die Dokumente und Informationen in eine strukturierte Wissensbasis überführen.
Der grundlegende Ablauf sieht so aus:
flowchart TD
A[Dokumente / Datenquellen] --> B[Text-Extraktion]
B --> C[Segmentierung / Chunking]
C --> D[Embedding-Erzeugung]
D --> E[Vektordatenbank]
Q[Benutzerfrage] --> QE[Query-Embedding]
QE --> R[Semantic Retrieval<br/>Suche nach relevanten Segmenten]
E --> R
R --> LLM[LLM mit Kontext]
LLM --> A2[Antwortgenerierung]Ziel dieser Pipeline ist es, Wissen effizient auffindbar und für KI-Systeme nutzbar zu machen.
Dokumentverarbeitung
Der erste Schritt besteht darin, relevante Dokumente zu erfassen und zu verarbeiten.
Typische Quellen sind beispielsweise:
- PDFs
- wissenschaftliche Arbeiten
- technische Dokumentationen
- interne Wissensdokumente
- strukturierte Datenquellen
Die Inhalte werden zunächst extrahiert und anschließend in kleinere, semantisch sinnvolle Abschnitte unterteilt.
Diese Segmentierung ist wichtig, damit spätere Suchanfragen möglichst präzise passende Inhalte finden können.
Embeddings und Vektordatenbank
Nach der Segmentierung werden für jeden Textabschnitt sogenannte Embeddings erzeugt.
Embeddings sind numerische Vektoren, die die Bedeutung eines Textes repräsentieren. Dadurch lassen sich Inhalte nicht nur über Schlüsselwörter, sondern über semantische Ähnlichkeit suchen.
Die erzeugten Embeddings werden anschließend in einer Vektordatenbank gespeichert.
Diese Datenbank ermöglicht es, zu einer Anfrage schnell die semantisch ähnlichsten Textabschnitte zu finden.
Retrieval und Antwortgenerierung
Wenn ein Nutzer eine Frage stellt, wird zunächst ein Embedding dieser Anfrage erzeugt.
Anschließend sucht die Vektordatenbank nach den relevantesten Textsegmenten. Diese werden dem Sprachmodell als Kontext übergeben.
Das Sprachmodell generiert daraufhin eine Antwort, die auf den gefundenen Informationen basiert.
Dieser Ansatz kombiniert damit zwei Stärken:
- präzise Informationssuche
- natürliche Sprachgenerierung
Warum RAG wichtig ist
In vielen praktischen Anwendungen reicht ein generisches Sprachmodell nicht aus.
Organisationen benötigen KI-Systeme, die:
- auf interne Dokumente zugreifen können
- aktuelle Informationen berücksichtigen
- nachvollziehbare Antworten liefern
- Halluzinationen reduzieren
RAG-Pipelines sind daher ein zentraler Baustein moderner KI-Anwendungen.
Ausblick
Die Kombination aus Wissenssystemen, Vektorsuche und Sprachmodellen eröffnet völlig neue Möglichkeiten für den Umgang mit Informationen.
Plattformen wie IdeaGraph oder Agira verfolgen genau diesen Ansatz: Wissen strukturiert erfassen, Kontext bereitstellen und KI-Systeme gezielt unterstützen.
RAG ist dabei nicht nur eine technische Lösung – sondern ein wichtiger Schritt hin zu wissensbasierten Softwareplattformen.